- Moegirl.ICU:萌娘百科流亡社群 581077156(QQ),欢迎对萌娘百科运营感到失望的编辑者加入!
User:ItMarki/关于Unicode编码
| “ | Everyone in the world should be able to use their own language on phones and computers. | ” |
| ——The purpose of Unicode | ||

简单介绍
很多人初次听到这个词汇,发懵,会发出“啊?Unicode这是什么啊?”的疑问,事实上不少IT人士对这个词汇也不是特别的熟悉。
Unicode名称也可以叫万国码,是一套编码系统,为了解决传统的字符编码方案所产生的局限性而推出的,为了满足跨语言,跨国的需求,Unicode的宗旨是:世间诸语,皆可电算处理。
但如果你看到这里还是不明白,那么你就看它的中文名,“万国”,这总明白吧?Unicode说白了就是任何的字符全部都支持!也就是說,我们现在所输入,在电脑上所使用的任何一个字符,全都是Unicode里的!我们中国,尤其是浏览器使用的语言一般的是GBK或者是Big-5的编码,但个别的浏览器使用Big-5编码有可能浏览网页时出现乱码的情况,所以各位如果在贴吧,BBS等地方看到有人输入字符的时候是一堆乱码,切勿喷,它的电脑就有可能使用的是Big-5的编码,使之和大部分用户的不兼容而出现了这种情况,理解万岁。
其实有一个和Unicode相联系的一个家伙,叫ASCII,它全称叫美国信息交换标准代码,ASCII是基于拉丁字母,西欧字母的基础上的一套编码程序,除此之外还有一些半角标点符号,控制字符等等,但是控制字符现在在一般人是不常用的所以不作过多的介绍了。ASCII现在在Unicode的区域是0000~007F。
但后期发现使用ASCII出现了诸多问题,一些其他国家的语言文字,特殊符号等等都无法进行正常的显示,因为ASCII只是针对的是美国的编码系统。例如英国的英镑符号(£),一些拉丁语字母表重音符号,带鄂化音的字符,使用斯拉夫字母表的希腊语、希伯来语、阿拉伯语和俄语,带有汉字系统的中国汉字,日语和朝鲜語等等。显然这并不能保证一致性,但这却显示了人们如何想尽办法为不同的语言来编码的。于是便有了Unicode这个家伙,也可以说ASCII是Unicode的前身,因为ASCII和Unicode都是由两位美国人发明的。
现在Unicode编码的字符已经扩充到了上万个字符,涉及到了各个领域,从现在的阿尔泰语系的语言,到中古时期的象形文字,楔形文字;从现在的各种数学符号,到各种各样的杂项工业符号,上至语言文学,下至各种各样的杂项符号,可以说Unicode现在已经遍及各个地区,我们生活的每一个地方都充斥着Unicode的影子。
但是啊,因为Unicode的字符众多,有时候你要去找一个字符会非常麻烦,于是现在的Unicode被分成了很多的范围,来表示这一范围内的字符是涉及什么的。
该编码表里的内容可能不是最新,一切请按照最新版本的编码表作为标准。
| 目前的Unicode编码所涉及的范围概览(文字类) |
|---|
 对于语系不理解的朋友,可以参考这张图片。 European Scripts 欧洲文字类
Armenian 亚美尼亚语
Carian 卡里安语 Caucasian Albanian 高加索阿爾巴尼亞语 Cypriot Syllabary 塞浦路斯音節文字 Cyrillic 西里尔语
Elbasan 愛爾巴桑語 Georgian 格鲁吉亚语
Glagolitic 格拉哥里语
Gothic 哥特语 Greek 希腊语
Latin 拉丁字母
Linear A A類線形文字 Linear B B類線形文字
Lycian 利西亚语 Lydian 吕底亚语 Ogham 欧甘语 Old Hungarian 古匈牙利语 Old Italic 古意大利语 Old Permic 老彼爾姆文 Phaistos Disc 斐斯托斯圓盤 Runic 卢恩符文 Shavian 萧伯纳字母 Modifier Letters 修饰符号 Modifier Tone Letters 修饰语音符号 Spacing Modifier Letters 间距修改符号 Superscripts and Subscripts 上下标 Combining Marks 组合符号 Combining Diacritical Marks 结合变音符号
Combining Diacritical Marks for Symbols 标识性结合变音符号 Combining Half Marks 结合半符号 African Scripts 非洲文字类 Adlam 阿德拉姆语 Bamum 巴姆穆语
Bassa Vah 巴萨瓦赫(巴萨华)语 Coptic 哥普特语
Egyptian Hieroglyphs 古埃及象形文字
Ethiopic 埃塞俄比亚语
Medefaidrin 梅德法伊德林文 Mende Kikakui 门地奇卡奎文 Meroitic 梅洛伊语
N'Ko 西非书面语言 Osmanya 奥斯曼亚语 Tifinagh 提非纳语 Vai 瓦伊语 Middle Eastern Scripts 中东文字类 Anatolian Hieroglyphs 安纳托利亚象形文字 Arabic 阿拉伯语
Aramaic, Imperial 皇室亚拉姆语 Avestan 阿维斯陀语 Chorasmian 花剌子模文字 Cuneiform 楔形文字(1MB)
Elymaic 埃利迈字母 Hatran 哈特兰文 Hebrew 希伯来语
Mandaic 曼达語 Nabataean 纳巴泰语 Old North Arabian 古北阿拉伯语 Old South Arabian 古南阿拉伯语 Pahlavi, Inscriptional 巴拉维铭文 Pahlavi, Psalter 巴拉维诗篇 Palmyrene 帕尔迈拉文 Parthian, Inscriptional 帕提亚碑铭体 Phoenician 腓尼基语 Samaritan 撒玛利亚语 Syriac 叙利亚語
Yezidi 雅兹迪文字 Central Asian Scripts 中亚文字类 Manichaean 摩尼语 Marchen 象雄语 Mongolian 蒙古语
Old Sogdian 老粟特语 Old Turkic 古突厥语 Phags-Pa 八思巴文 Sogdian 粟特语 Soyombo 索永布蒙古文 Tibetan 藏语 Zanabazar Square 札那巴札爾方形字母 South Asian Scripts 南亚文字类 Ahom 阿霍姆语 Bengali and Assamese 孟加拉语和阿萨姆语 Bhaiksuki 拜克舒基文 Brahmi 婆罗米语 Chakma 恰克玛语 Devanagari 天城文
Dives Akuru 迪维希阿库鲁文字 Dogra 多格拉语 Grantha 古兰塔语 Gujarati 古吉拉特语 Gunjala Gondi 古吉拉共地文字 Gurmukhi 果鲁穆奇语 Kaithi 凯提文 Kannada 卡纳达语 Kharoshthi Khojki 可吉语
Lepcha 雷布查语 Limbu 林布文 Mahajani 马哈佳尼文 Malayalam 马拉亚拉姆语 Masaram Gondi 马萨拉姆共地文字 Meetei Mayek 曼尼普尔文
Modi 莫季语 Mro 默文 Multani 马洛语 Nandinagari 南迪城文 Newa 尼泊尔纽瓦字母 Ol Chiki 桑塔利语 Oriya (Odia) 奥里亚语(奥迪亚语) Saurashtra 索拉什特拉语 Sharada 沙拉达普拉语 Siddham 悉昙语 Sinhala 僧伽罗语
Sora Sompeng 索拉桑蓬文 Syloti Nagri 塞洛提纳格瑞文 Takri 塔卡里文 Tamil 泰米尔语 Telugu 泰卢固语 Thaana 它拿语 Tirhuta 提尔胡塔文 Vedic Extensions 吠陀梵文扩展 Wancho 文乔文 Warang Citi 瓦兰齐地文 Southeast Asian Scripts 东南亚文字类
Hanifi Rohingya 哈乃斐罗兴亚文字 Kayah Li 克耶黎文 Khmer 高棉语
Lao 老挝语 Myanmar 缅甸语
New Tai Lue 新傣仂文 Nyiakeng Puachue Hmong 创世纪苗文 Pahawh Hmong 帕哈苗文 Pau Cin Hau 袍清豪文 Tai Le 德宏傣文 Tai Tham 老傣文 Tai Viet 越南傣文 Thai 泰语 Indonesia & Oceania Scripts 印度尼西亚和大洋洲文字类 Balinese 巴厘文 Batak 巴塔克文 Buginese 布吉斯文 Buhid 布迪文 Hanunoo 哈努诺文 Javanese 爪哇语 Makasar 玛卡莎文 Rejang 勒姜(拉让)语 Sundanese
Tagalog 他加禄语 Tagbanwa 塔格巴努亚文 East Asian Scripts 东亚文字类 Bopomofo 注音符号
CJK Unified Ideographs (Han) 中日韩統一表意文字(汉字)
CJK Compatibility Ideographs 中日韩兼容表意文字
CJK Radicals / KangXi Radicals 中日韩部首/康熙部首
Hangul Jamo 谚文字母
Hangul Syllables 谚文音节 Hiragana 平假名 Kana Extended-A 假名扩展A Kana Supplement 假名补充 Small Kana Extension 小型假名扩展 Kanbun 象形字注释标志 Katakana 片假名
Khitan Small Script 契丹小字 Lisu 傈僳语
Miao 柏格里苗文 Nushu 女书 Tangut 唐古特(西夏)文
Yi 彝语
American Scripts 美洲文字类 Cherokee 切罗基语
Deseret 德泽雷特语 Osage 奥色治语 Unified Canadian Aboriginal Syllabics 统一加拿大原住民音节文字
Other 其他类
|
| 目前的Unicode編碼所涉及的範圍概覽(符号和标点类) |
|---|
|
Notational Systems 符号系统 Braille Patterns 盲文点阵 Musical Symbols 音乐符号
Duployan 杜普雷严速记
Sutton SignWriting 萨顿书写符号 Punctuation 标点符号 General Punctuation 一般标点符号
CJK Symbols and Punctuation 中日韩符号和标点
CJK Compatibility Forms 中日韩兼容形式
Alphanumeric Symbols 字母数字类符号 Letterlike Symbols 字母符号
Mathematical Alphanumeric Symbols 数学用字母数字符号 Arabic Mathematical Alphabetic Symbols 阿拉伯语数学用字母符号 Enclosed Alphanumerics 封闭式字母数字
Enclosed CJK Letters and Months 封闭式中日韩字母和月份
CJK Compatibility 中日韩兼容形式
Technical Symbols 技术性符号
Numbers & Digits 数字类
ASCII Digits ASCII数字
Common Indic Number Forms 常用印第安数字 Coptic Epact Numbers 科普特数字 Counting Rod Numerals 算筹记数式 Cuneiform Numbers and Punctuation 楔形文字数字和标点符号 Indic Siyaq Numbers 印度西亚克数字 Mayan Numerals 玛雅数字 Number Forms 数字形式 Ottoman Siyaq Numbers 奥斯曼西亚克数字 Rumi Numeral Symbols 鲁米数字符号 Sinhala Archaic Numbers 僧伽罗语古数字 Super and Subscripts 上标和下标 Mathematical Symbols 数学符号 Arrows 箭头
Mathematical Alphanumeric Symbols 数学字母数字符号
Mathematical Operators 数学运算符
Geometric Shapes 几何图形
Emoji & Pictographs 表情符号和象形文字 Dingbats 装饰符号(丁贝符)
Emoticons 表情符号 Miscellaneous Symbols 杂项符号 Miscellaneous Symbols And Pictographs 杂项符号和象形文字 Supplemental Symbols and Pictographs 追加符号和象形文字 Symbols and Pictographs Extended-A 符号和象形文字扩展A Transport and Map Symbols 运输和地图符号 Other Symbols 其他符号 Alchemical Symbols 炼金术符号 Ancient Symbols 古代符号 Currency Symbols 货币符号
Game Symbols 游戏符号
Miscellaneous Symbols and Arrows 杂项符号和箭头 Symbols for Legacy Computing 传统计算符号 Yijing Symbols 易经六十四卦符号
Specials 特殊
Specials 特殊 Tags 标签符号 Variation Selectors 异体字选择符
Private Use 私用
Surrogates 代理字
Noncharacters in Charts 表格中的非字符 Noncharacters in blocks 区块中的非字符
Noncharacters at end of ... 非字符的结尾在……
|
于是,这就涉及到了一些所谓的“黑科技”,你可以在Unicode里找到相应的字符,进行各种组合,来做到一般人做不到的效果。
“黑科技”

根式
看此根式:∜1̅8̅,其中18上的两横线是U+0305的编码,四次根符号的位置则是在U+221C。
或者是三次根,二次根也可以做到这种效果,二次根的根号事实上就是使用对勾代替,比如√9̅=3,∛1̅7̅=2.5712815906582353554531872087397...
在一些条件允许的网页当中(比如说以维基百科为蓝本的网页),你可以使用以下的代码,效果会好很多。亦或者直接使用Template:MathJax。这个模板几乎就是天衣无缝的。
√<span style="border-top:1px solid #000;">18</span>
范例一:∜18=2.059767143907117755830277255201...,√9=3,∛17=2.5712815906582353554531872087397...
该模板我并没有放入User:FITZGERALD/萌娘百科常用代码一览当中,因为我觉得对于我来说这个模板未来的使用可能性并不高,而且这个模板较难上手。
“DIY分数”
先输入一个数字,之后输入分数线,然后再输入一个数字。咱们搞一个复杂一点的分数,比如100⁄9。
注意:
- 在大部分的字体当中看到的是“100/9”这样子,也属于正常情况,大部分的地方都会显示成“100/9”这样。但在Noto字体中,上下的数字会全部变小,就好像真正的书写分数一样。
- 有且只有连贯数字才会变小,而且如果没有非数字字符的话会一直这样连贯下去,直到有非数字字符为止。e.g.:b⁄a,10b99⁄9a9a9,0123456789⁄9876543210。
除了Unicode编码当中现成的一些分数,“⅐⅑⅒⅓⅔⅕⅖⅗⅘⅙⅚⅛⅜⅝⅞↉⅟这啥?◯分之一?”之外,现在有了分数线“⁄”(U+2044),我们便可以自己“DIY分数”了!
常见数学符号
高中数学必修1里讲述的集合常用的符号,比如说“∈”为属于,“∉”为不属于,“∅”为空集,“∁”为补集这和课本上显示的不太一样啊,“∩”为交集,倒过来就是并集“∪”了呗,“⫋”为某是某的真子集,或者是积分“∫”,二重积分“∬”,三重积分“∭”,围道积分“∮”,啊等等……这里就不过多举例了。
数学“圆○”这一章节,其中若表示两点之间的圆弧可以用弧AB表示,写作A͡B,这个弧则是U+0361的字符。
使用例:
有許多人想知道我學習,玩遊戲等等的效率是多少,這裡我分成兩種情況討論:
當我學習時,𝜂我受外界溫度𝑡影響,假定𝑡為橫坐標,𝜂我為縱坐標,那麼:
- 當𝑡⩽19時,𝑡值越小,𝜂我值也越小,因此在這一範圍內𝜂我和𝑡成正比。函數圖像近似等於𝑦=0.18𝑥+56 (-300<𝑥<19)
- 但當𝑡>19時,𝑡值變大𝜂我值反而變小,此時𝜂我與𝑡成反比,此時函數圖像近似等於𝑦=$1140 \over x$ (19<𝑥<273.15)
當𝑡>273.15或𝑡<-273.15時,𝜂我=0。
因此若以現在的標準計算,𝜂我≈66.67%
當我玩遊戲時,一般情況下100%>𝜂我⩾90%,此時的𝜂我不受任何外界因素的影響,只受內因的影響,偶爾會出現90%>𝜂我>85%的情況,但出現這種情況大部分時間是我處在感冒狀態。
音乐简谱
1,2,3,4,5,6,7对应的是do,re,mi,fa,sol,la,si,高音则需要上面加一点,比如高音的do用简谱表示成“1̇”。
再就是对于四分之一音和八分之一音的表示: ͟5͟6 6͇5͇3 ͟0͟3|5,一横线的是U+035F,而双横线的则是U+0333。(你若是想把四分之一音说成是下划线也可以。)
化学方程式
化学一定要涉及到化学方程式,那么在涉及到的这些化学方程式里,有的一些会在等号上面注明反应条件,其中加热的条件,可以直接在中间的等号上方画上一个三角形(△),但化学方程式里的三角形和等号是一个在上,一个在下,这可如何是好?咱们先以NaHCO₃受热分解的化学方程式为例:2NaHCO₃≜Na₂CO₃+H₂O+CO₂↑
看清楚了!没有错!这是可以做到的!
首先对于这个“≜”符号,你可以在U+225C的区域找到它,其次是这些下标数字,你在U+2080这一行里全部都能找得到,这里因为时间关系不全部一一列举出来了。
化学的离子也是可以做到的,比如像酸根离子:SO₄²⁻,CO₃²⁻,金属离子:NH₄⁺,Fe²⁺,Fe³⁺,Na⁺,K⁺,非金属离子Cl⁻,Br⁻,I⁻,又或者是氢氧根离子:OH⁻,等等,也都在上面提到的那里可以找得到,各位到时候就自己去寻找吧。
MathJax的一个优势在于,它可以表示化学方程式当中任何反应条件,甚至是汉字都没问题。而仅靠Unicode则只能表示加热条件,且还只能是简略的符号表达形式。
删除相关
可以在没有删除线标准的前提下作出删除字符的效果,比如:F̶i̶t̶z̶g̶e̶r̶a̶l̶d̶,删除线所在的码位为U+0336,你可以拿它和后面这个对比下。Fitzgerald。
模拟笔在纸上划掉错误的地方的样子:F̷̸̸i̷̸̸t̷̸̸z̷̸̸g̷̸̸e̷̸̸r̷̸̸a̷̸̸l̷̸̸d̷̸̸,看呐,乱糟糟一團。 ( ̷·̷ ̷ω̷ ̷·̷ ) ,这些字符的范围全在0300—036F中,各位到时自行去寻找吧。
反转和倒转相关
甚至是让你强行右至左书写,右至左观看这一句话,外人会以为这全是黑科技,其实呢?这一点都不神秘,如果你对Unicode十分了解,那么你所看到的这一切全都可以用Unicode来解释,它就会变成司空见惯的现象。
↑这句话要反过来看,如果你看不明白请点开下面的原文版本,这里使用的是U+202E的强制右至左书写的字符。
※注意,我绝对没有倒过来输入这句话,你用脚趾头想想,这么长的一段文字,誰會对这一行长文字花那么长的时间去一点一点的把它反过来?想想都不可能。
| 原文 |
|---|
|
甚至是让你强行右至左书写,右至左观看这一句话,外人会以为这全是黑科技,其实呢?这一点都不神秘,如果你对Unicode十分了解,那么你所看到的这一切全都可以用Unicode来解释,它就会变成司空见惯的现象。 |
更有倒翻的英文字母,比如:˙ʞ plɐɹəᵷzʇᴉɟ,像这种的倒翻英文字母如果自己一个一个的弄会很麻烦,字符百科有专门的倒翻的网页,直接去那里搞就可以,比较方便。但有一点你需要注意:倒翻英文字母目前仅支持小写的英文字母。
目前关于各种拉丁字母的倒翻字符整理(摘自某知乎上的文章):
| 点此展开 |
|---|
|
a→ɐ(U+0250),這個字母也表示次开央元音。 b→q,使用拉丁字母即可。 c→ɔ(U+0254),這個字母也表示半开后圆唇元音。 d→p,使用拉丁字母即可。 e→ǝ(U+01DD),這個字母也表示中央元音。部分機型不支持這個字符,亦可以用ə(U+0259),效果等同。 f→ɟ(U+025F),這個字母也表示浊硬颚塞音,嚴格來說該字母是無點j加上粗線。 g→ᵷ(U+1D77),這個存在爭議,我本人不推薦使用ƃ(U+0183)和ɓ(U+0253)。Unicode字符百科生成的時候使用的是ƃ,而ɓ可以使用在一些機型不支持ᵷ的情況下使用,儘管效果並不是很好。 h→ɥ(U+0265),這個字母也表示浊圆唇硬颚近音。 i→ᴉ(U+1D09),不推薦使用ı(U+0131)。 j→ſ̣,存在爭議,這種屬於附加標的文字,是由ſ(U+017F)+(U+0323)組合而成,Unicode字符百科給出的倒轉形態則是ɾ(U+027E),效果更糟。儘管我本人並不推薦使用結合文字。 k→ʞ(U+029E),曾用以表示清小舌塞音/q/或一种祖魯语中出现的吸气音。 l→ן(U+05DF),这个是希伯来语字母 nun 的词尾形式,Unicode字符百科中,給出該字符的倒轉是無變化。由於希伯來語的書寫方向是從右至左,加之在一些使用帶有襯線體的字體當中效果並不是很好。 m→ɯ(U+026F),這個字母也表示闭后不圆唇元音,請注意,俄語當中的字母ш,手寫體是和ɯ相同的。 n→u,使用拉丁字母即可。 o→o,無變化。 p→d,使用拉丁字母即可。 q→b,使用拉丁字母即可。 r→ɹ(U+0279),這個字母也表示齿龈无擦通音。 s→s,無變化。 t→ʇ(U+0287),這個字母也表示舌尖搭嘴音的一种代替写法,通常用的是/ǀ/。 u→n,使用拉丁字母即可。 v→ʌ(U+028C),這個字母也表示半开后不圆唇元音。 w→ʍ(U+028D),這個字母也表示清圆唇软颚近音。 x→x,無變化。 y→ʎ(U+028E),這個字母也表示硬颚边音。 z→z,無變化。 |
中日韩字符集兼容
在Unicode当中,有一个3300—33FF的区块,这个区块的名字叫做中日韩字符集兼容,该区块下有一些由多个字母组成的占一个单位的字符,而这些字符通常是表示物理,数学,化学,天文地理等领域的一些常用单位,你可以点击下方来展开查询它们都代表什么意思。
| 点此展开 |
|---|
|
㍱:百帕(斯卡)——压强 ㍲:道(尔顿)——原子质量 ㍳:天文单位制(Astronomical unit) ㍴:巴(尔)——压强 ㍵:输出电压(output Voltage) ㍶:秒差距——距离 ㍷:分米——距离 ㍸:平方分米——面积 ㍹:立方分米——容积 ㍺:国际单位制(International Units) ㎀:皮安(培)——电流 ㎁:纳安(培)——电流 ㎂:微安(培)——电流 ㎃:毫安(培)——电流 ㎄:千安(培)——电流 ㎅:千字节——数据 ㎆:兆字节——数据 ㎇:吉字节——数据 ㎈:卡(路里)——热量 ㎉:千卡(路里)——热量 ㎊:皮法(拉第)——电容 ㎋:纳法(拉第)——电容 ㎌:微法(拉第)——电容 ㎍:微克——质量 ㎎:毫克——质量 ㎏:千克——质量 ㎐:赫(兹)——电频 ㎑:千赫(兹)——电频 ㎒:兆赫(兹)——电频 ㎓:吉赫(兹)——电频 ㎔:太赫(兹)——电频 ㎕:微升——容积 ㎖:毫升——容积 ㎗:分升——容积 ㎘:千升——容积 ㎙:飞米——长度 ㎚:纳米——长度 ㎛:微米——长度 ㎜:毫米——长度 ㎝:厘米——长度 ㎞:千米——长度 ㎟:平方毫米——面积 ㎠:平方厘米——面积 ㎡:平方米——面积 ㎢:平方千米——面积 ㎣:立方毫米——容积 ㎤:立方厘米——容积 ㎥:立方米——容积 ㎦:立方千米——容积 ㎧:米每秒——速度 ㎨:米每秒平方——加速度 ㎩:帕(斯卡)——压强 ㎪:千帕(斯卡)——压强 ㎫:兆帕(斯卡)——压强 ㎬:吉帕(斯卡)——压强 ㎭:弧度——数学 ㎮:弧每秒——角速度 ㎯:弧每秒平方——角加速度 ㎰:皮秒——时间 ㎱:纳秒——时间 ㎲:微秒——时间 ㎳:毫秒——时间 ㎴:皮伏(特)——电压 ㎵:纳伏(特)——电压 ㎶:微伏(特)——电压 ㎷:毫伏(特)——电压 ㎸:千伏(特)——电压 ㎹:兆伏(特)——电压 ㎺:皮瓦(特)——功率 ㎻:纳瓦(特)——功率 ㎼:微瓦(特)——功率 ㎽:毫瓦(特)——功率 ㎾:千瓦(特)——功率 ㎿:兆瓦(特)——功率 ㏀:千欧(姆)——电阻 ㏁:兆欧(姆)——电阻 ㏂:上午(ante meridiem) ㏃:贝可——放射性强度 ㏄:立方厘米——容积 ㏅:坎(德拉)——发光强度 ㏆:库仑每千克——放射量 ㏇:有限責任公司(Company) ㏈:分贝——声音强度 ㏉:戈瑞——吸收辐射量 ㏊:公顷——面积 ㏋:马力——功率 ㏌:英寸——长度 ㏍:千开(尔文)——温度 ㏎:马达常数(Motor constants) ㏏:千吨——质量 ㏐:流明——光照度 ㏑:自然对数——数学 ㏒:对数——数学 ㏓:勒(克斯)——光照度 ㏔:毫巴(尔)——压强 ㏕:密耳——长度 ㏖:摩尔——物质的量 ㏗:酸碱度(pondus Hydrogenii) ㏘:下午(post meridiem) ㏙:百万分率(Parts per million) ㏚:复杂度——数学 ㏛:球面度——数学 ㏜:希沃特——吸收辐射量 ㏝:韦伯——磁通量 ㏞:伏(特)每米——电场强度 ㏟:安(培)每米——磁场强度 ㏿:加仑——容积 |
小结
如果你家的电脑依然是Windows XP或者比这更低的系统,或是手机安卓系统在5.0或者比这更往下,那么有很多的字符会无法显示,会被“�”或“□”[1],甚至是一个什么都不显示的类似空格的字符所替换,若发生这种情况,有两种解决措施:
- 升级系统;但这个大多数人并不一定能够接受。
- 安装相应区域下的字体文件;一般电脑自带的能够支持大部分区域的字符有Dotom,Tahoma等等。而Noto字体等都可以说是应对这种方法的不二之选。
总之,你想要的,这里全都有。这里的奥秘很多,需要各位自己慢慢探索,我因为时间的关系,不能全部列出。如有需要,也可以去帮助:特殊符号表来查看我没有提及和列出的地方虽然这个页面提及和列出的远没有我这里的详细。
Unicode编码表历代版本一览
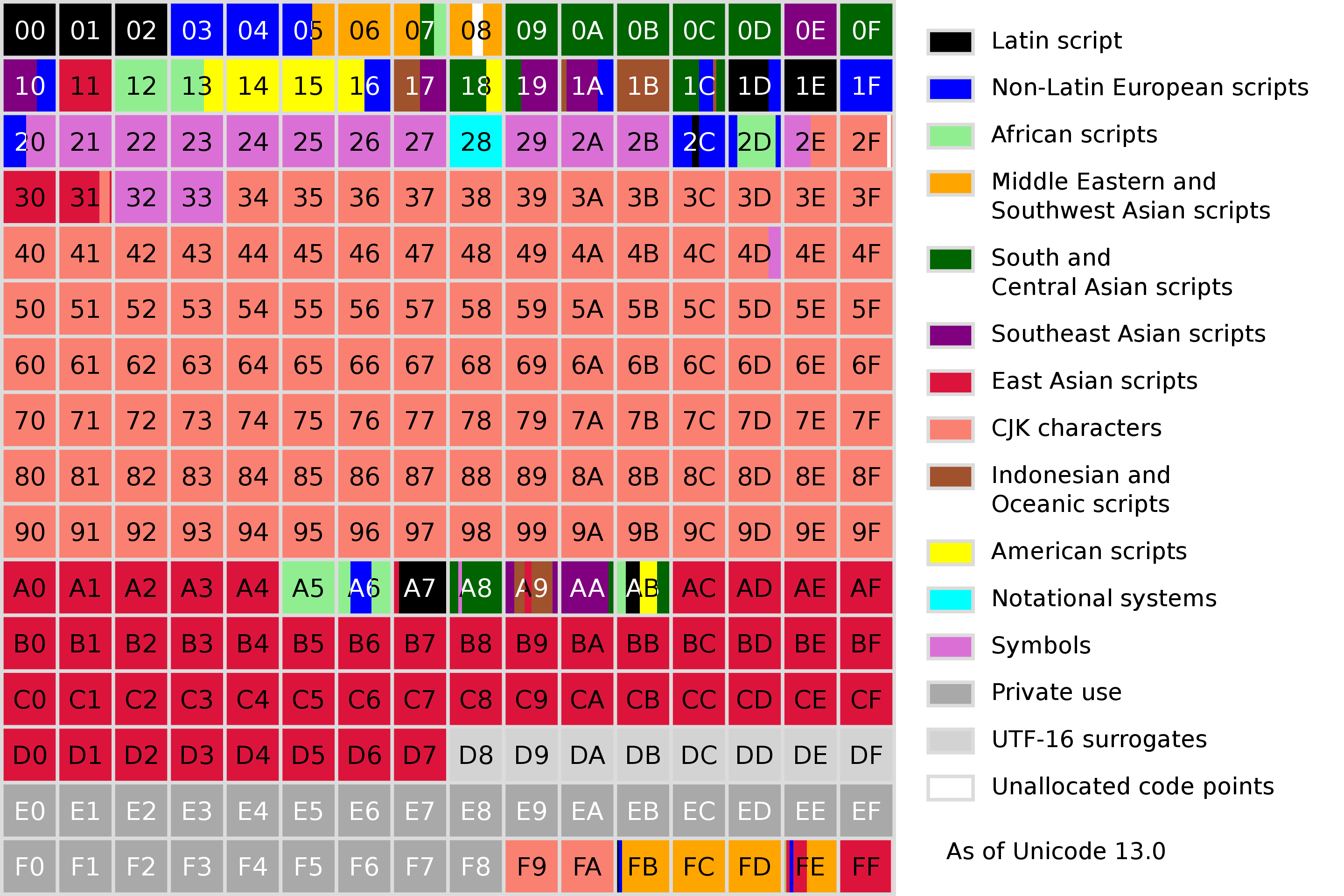
码点,不同的颜色表示代表该码点属于不同的分类,以下同此。
拉丁文字系,非拉丁—欧洲文字系,非洲文字系,中东和西南亚文字系,南亚和中亚文字系,
东南亚文字系,东亚文字系,中日韩汉字,印度尼西亚和大洋文字系,美洲文字系,
记号系统,符号,私用区,UTF-16代理区,未分配码点
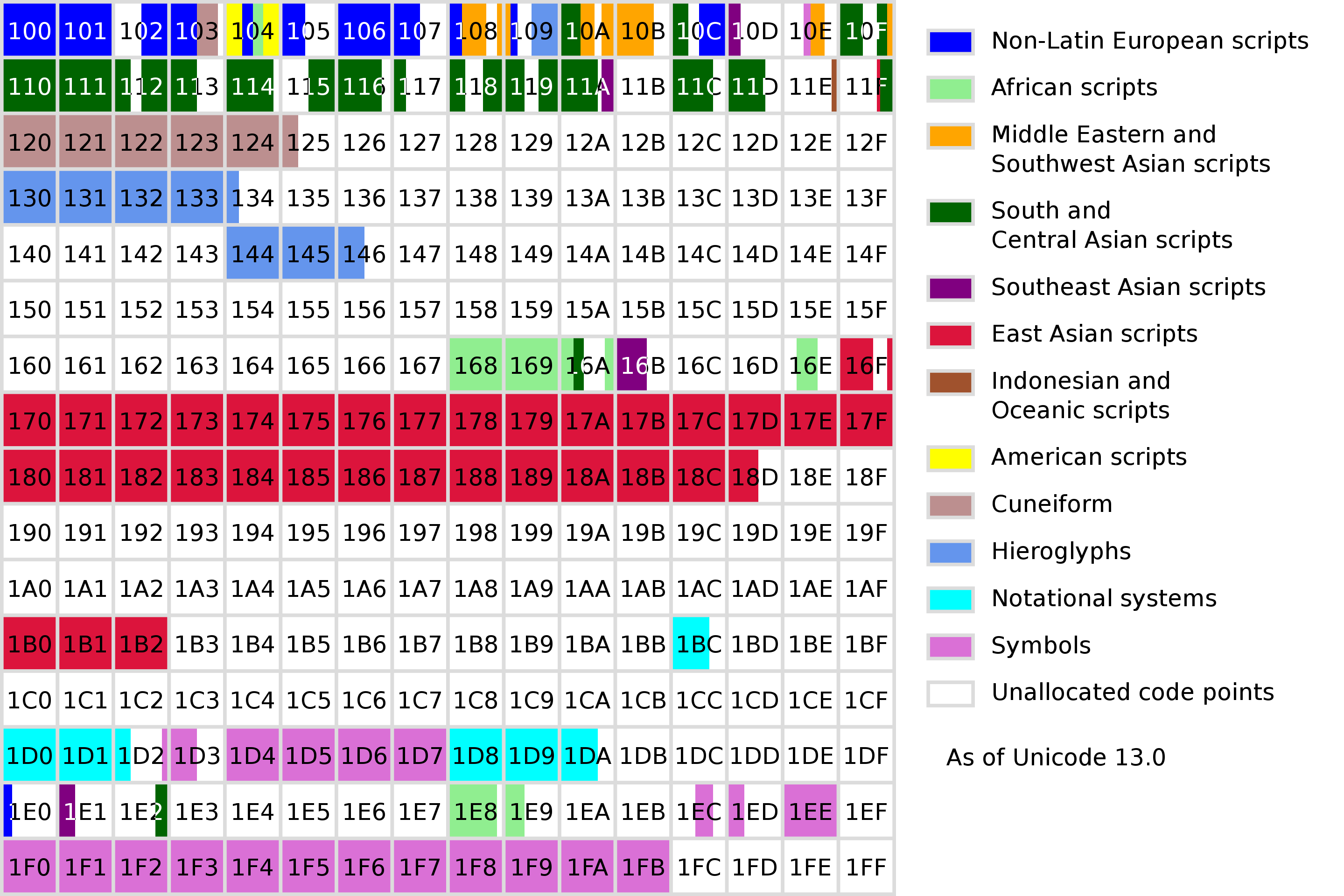

| 版本号 | 发布日期 | 该阶段总分区数 | 该阶段总字符数 | 已知的扩增 |
|---|---|---|---|---|
| 1.0.0 | 1991/10 | 24 | 7161 | 最初包含的文字有:阿拉伯字母、亚美尼亚字母、孟加拉文、注音符号、西里尔字母、天城文、格鲁吉亚字母、希腊字母、古吉拉特文、古木基文、谚文、希伯来字母、平假名、卡纳达文、片假名、寮文字、拉丁字母、马拉亚拉姆文、奥里亚文、泰米尔文、泰卢固文、泰文字、藏文。 |
| 1.0.1 | 1992/6 | 25 | 28359 | 定义中日韩統一表意文字最初的20902个字。 |
| 1.1 | 1993/6 | 24 | 34233 | 于原有2350个谚文字母的基础上新增4306个谚文字母,移除藏文。 |
| 2.0 | 1996/7 | 25 | 38590 | 移除原有的谚文字母设置,于新的编码范围更换成11172个新的谚文字母。藏文重新加入,但编码位置更换。代理字符机制建立,并将第15与第16平面分配给私人使用区。 |
| 2.1 | 1998/5 | 25 | 38952 | 新增欧元符号与对象替换字符。 |
| 3.0 | 1999/9 | 38 | 49259 | 新增切罗基文、埃塞俄比亚语、高棉语、蒙古语、缅甸语、欧甘字母、卢恩字母、僧伽罗语、叙利亚語、它拿字母、加拿大原住民音节文字、彝文,以及部分盲文图案。 |
| 3.1 | 2001/3 | 41 | 94205 | 新增犹他字母、哥特字母、古意大利字母、音乐符号、拜占庭音乐符号,追加了42711个中日韩統一表意文字(扩展区B)。 |
| 3.2 | 2002/3 | 45 | 95221 | 新增菲律宾文字:布锡文、哈努诺文、他加禄语、塔格巴奴亚文。 |
| 4.0 | 2003/4 | 52 | 96447 | 新增塞浦路斯音节文字、林布字母、线形文字B、奥斯曼亚字母、萧伯纳字母、德宏傣文、乌加里特字母,以及六十四卦。 |
| 4.1 | 2005/3 | 59 | 97720 | 新增布吉文、格拉哥里字母、佉卢文、西双版纳傣文、古波斯语、锡尔赫特文、提非纳文。科普特字母从希腊语区块中分離了出来。新增了古希腊音乐符号。 |
| 5.0 | 2006/7 | 64 | 99089 | 新增巴厘语、楔形文字、西非书面文字、八思巴文、腓尼基字母。 |
| 5.1 | 2008/4 | 75 | 100713 | 新增卡利亚语、占婆字母、克耶黎语、绒巴文、利西亚语、吕底亚语、桑塔利文、拉让文、索拉什特拉文、巽他语、瓦伊语。同时增加了斐斯托斯圆盘、麻将、多米诺骨牌上的符号。对缅甸语做了重要的补充,追加了手抄缩写的额外字母,追加了大写ẞ。 |
| 5.2 | 2009/10 | 90 | 107361 | 新增阿维斯陀语、巴姆穆文字、埃及象形文字(加汀纳符号表,涵盖1071个符号)、亚拉姆语、巴拉维碑铭体、帕提亚碑铭体、爪哇语、凱提文、老傈僳文、曼尼普尔文、南阿拉伯字母、古突厥语、撒玛利亚语、老傣文、傣越文。追加4149个中日韩統一表意文字(扩展区C),同时扩展了古韩语和吠陀梵语的字符。 |
| 6.0 | 2010/10 | 93 | 109449 | 新增巴塔克字母、婆罗米文字、曼达字母、纸牌符号、交通标志、地图符号、炼金术符号、颜文字、绘文字。追加222个额外的中日韩統一表意文字(扩展区D)。 |
| 6.1 | 2012/1 | 100 | 110181 | 新增查克马字母、麦罗埃文、麦罗埃象形文字、柏格里苗文、夏拉达文、索拉僧平文字、泰克里文。 |
| 6.2 | 2012/9 | 100 | 110182 | 土耳其里拉符号。 |
| 6.3 | 2013/9 | 100 | 110187 | 5个双向排版符号。 |
| 7.0 | 2014/6 | 123 | 113021 | 新增巴萨字母、高加索阿尔巴尼亚字母、杜普雷严速记、爱尔巴桑字母、古兰塔文、可吉文、库达瓦迪文、线形文字A、马哈佳尼文、摩尼教字母、门得文字、莫迪字母、默文、纳巴泰字母、古北阿拉伯文、古彼尔姆文、杨松录苗文、帕米拉文字、袍清豪文、诗篇巴列维文、悉昙文字、提尔胡塔文、瓦兰齐地文,以及装饰符号。 |
| 8.0 | 2015/6 | 129 | 120737 | 增加阿洪姆文、安纳托利亚象形文字、哈坦文、穆尔塔尼文、古匈牙利字母、书写符号、5771个中日韩統一表意文字(扩展区E)、切罗基语小写字母,以及5种绘文字肤色修改字符。 |
| 9.0 | 2016/6 | 135 | 128237 | 新增阿德拉姆字母、比奇舒奇文、象雄文、尼泊尔纽瓦字母、欧塞奇字母、西夏文,以及74个绘文字。 |
| 10.0 | 2017/6 | 139 | 136755 | 札那巴札尔、索永布文字、马萨拉姆贡德文字、女书、变体假名(非标准平假名)、7494个中日韩統一表意文字(扩展区F),以及56个绘文字。 |
| 11.0 | 2018/6 | 146 | 137374 | 多格拉文、格鲁吉亚文骑士体大写字母、贡贾拉贡德文、哈乃斐罗兴亚文字、望加锡文、梅德法伊德林文、老粟特文、粟特文,以及145个绘文字。 |
| 12.0 | 2019/3 | 150 | 137928 | 埃利迈文、南迪城文、创世纪苗文、文乔文,以及61个绘文字。 |
| 12.1 | 2019/5 | 150 | 137929 | 只在U+32FF新增了一个字符,即日本新年号令和的和字。 |
| 13.0 | 2020/3 | 154 | 143924 | 花剌子模语、迪维西语的岛字母、契丹小字、库尔德语字母的雅兹迪体、4969个新增的中日韩统一表意文字(包括4939个位于扩展区G)、书写豪萨语用的阿拉伯附加字母、沃洛夫语、其他非洲语言、在巴基斯坦书写印德科语和旁遮普语的补充字元、粤语用的注音符号、共享创意授权符号、七十或八十年代电讯用图符、55个绘文字。 |
其中第一辅助平面又称多文种补充平面(Supplementary Multilingual Plane,缩写SMP,或简称Plane 1),摆放拼音文字(主要为现时已不再使用的古老文字)、手写文字、音符、绘文字和其他图形符号。用于学者的专业论文中使用的古老或过时的语言书写符号,以及网络通信等使用的表情符号。范围在U+10000~U+1FFFD。
第二辅助平面又称为表意文字补充平面(Supplementary Ideographic Plane,缩写SIP,或简称Plane 2),整个范围在U+20000~U+2FFFD。整个平面配置的都是一些罕用的汉字或地区的方言用字,如粤语用字及越南语的喃字。现时摆放了“中日韩统一表意文字扩展B区”(43253个汉字)、“中日韩统一表意文字扩展C区”(4149个汉字)、“中日韩统一表意文字扩展D区”(222个汉字)、“中日韩统一表意文字扩展E区”(5762个汉字)、“中日韩统一表意文字扩展F区”(7473个汉字)以及中日韩兼容表意文字增补(CJK Compatibility Ideographs Supplement)。
第三辅助平面已有相关编码提案。本平面现已用来摆放汉字扩展区G,并规划用于摆放甲骨文、金文、小篆、中国战国时期文字等。按Unicode官网的路线图,计划分配的编码区段为:
- U+30000~U+31389:扩展区G(已发布)。
- U+31400~U+33D1F:小篆(提案已提交)。
- U+33E00~U+355FF:甲骨文(提案已提交)。
第十四辅助平面又称特别用途补充平面(Supplementary Special-purpose Plane,简称SSP),当前仅摆放“语言编码标签”和“字形变换选取器”,它们都是控制字符。范围在U+E0000~U+E01FF。
第十五至十六辅助平面都是私人使用区。它们的范围是U+F0000~U+FFFFD及U+100000~U+10FFFD,增加了补充私用区A和补充私用区B。由此可见这两个平面所投入使用的字符已经确定。
- ↑ 这种情况下因其字符形状,被俗称“豆腐块”。Noto系列字体的“Noto”意为“No tofu”,这里的“tofu”即为前面所提及的不能显示字符的“豆腐块”。